大多数现代操作系统旨在尝试从底层硬件资源中提取最佳性能。这主要是通过两个主要硬件资源的虚拟化来实现的:CPU 和内存。现代操作系统提供了一个多任务环境,基本上为每个任务提供了自己的虚拟 CPU。任务通常不知道它不独占 CPU 使用权这一事实。
类似地,内存虚拟化是通过给每个任务自己的虚拟内存地址空间来实现的,然后将其映射到系统的真实内存上。同样,任务通常不知道它的虚拟内存地址可能不会映射到实内存中的相同物理地址。
CPU 虚拟化是通过在多个任务之间“共享”CPU 来实现的——也就是说,每个正在运行的任务定期获得一小部分 CPU。从多个可用的可运行任务中一次选择一个任务的算法称为调度器,选择下一个任务的过程称为调度。
调度程序是任何操作系统最重要的组件之一。由于几个原因,实现调度算法很困难。首先,一个可接受的算法必须分配 CPU 时间,这样优先级较高的任务(例如 Web 浏览器等交互式应用程序)优先于低优先级任务(例如程序编译等非交互式批处理)。同时,调度程序必须防止低优先级进程饥饿。换句话说,无论有多少高优先级进程在争夺 CPU 时间,最终都必须允许低优先级进程运行。调度程序也必须精心设计,以便进程看起来同时运行,而不会对系统吞吐量产生太大影响。
对于像 GUI 这样的交互式进程,理想的调度程序会给每个进程在 CPU 上占用很少的时间,并在进程之间快速循环。因为用户希望交互式进程立即响应输入,所以理想情况下,用户输入和进程执行之间的延迟应该是人类察觉不到的——最多在 50 到 150 毫秒之间。
对于非交互式进程,情况正好相反。进程之间的切换或上下文切换是一项相对昂贵的操作。因此,处理器上更多的时间片和更少的上下文切换可以提高系统性能和吞吐量。调度算法必须在所有这些相互竞争的需求之间取得平衡。
像大多数现代操作系统一样,Linux 是一个多任务操作系统,因此它有一个调度程序。 Linux 调度程序随着时间的推移而发展。
1. O(1) 调度器
随着内核 2.6 的发布,Linux 调度程序被彻底改革。这个新的调度器被称为 O(1) 调度器——O(…) 被称为“大 O 表示法”。选择这个名称是因为调度程序的算法需要恒定的时间来做出调度决策,而不管任务数量如何。 O(1) 调度器使用的算法依赖于活动和过期的进程数组来实现恒定的调度时间。每个进程都有一个固定的时间段,之后它被抢占并移动到过期的数组中。一旦活动阵列中的所有任务都用完它们的时间片并移至过期阵列,就会发生阵列切换。此开关使活动阵列成为新的空过期阵列,而过期阵列成为活动阵列。
该算法的主要问题是用于将任务标记为交互式或非交互式的复杂启发式方法。该算法试图通过分析平均睡眠时间(进程等待输入所花费的时间)来识别交互式进程。长时间休眠的进程可能正在等待用户输入,因此调度程序假定它们是交互式的。调度程序为交互式任务提供优先级奖励(以获得更好的吞吐量),同时通过降低非交互式任务的优先级来惩罚非交互式任务。用于确定任务交互性的所有计算都很复杂,并且容易发生潜在的错误计算,从而导致交互过程中出现非交互行为。
正如我在本文后面解释的那样,CFS 不受任何此类计算的影响,只是尝试对系统中运行的每个任务保持“公平”。
2. 完全公平的调度程序(CFS)
根据 CFS 的作者 Ingo Molnar 的说法,它的核心设计可以用一句话概括:“CFS 基本上是在真实硬件上模拟一个‘理想的、精确的多任务 CPU’。”
让我们试着理解“理想的、精确的、多任务处理的 CPU”是什么意思,因为 CFS 试图模拟这个 CPU。 “理想的、精确的、多任务的 CPU”是一种硬件 CPU,它可以同时(并行)运行多个进程,为每个进程提供平等的处理器能力(不是时间,而是能力)。如果单个进程正在运行,它将获得 100% 的处理器功率。对于两个进程,每个进程都将拥有 50% 的物理功率(并行)。 类似地,如果有四个进程在运行,每个进程都会并行获得精确的 25% 的物理 CPU 能力,依此类推。 因此,这个 CPU 对系统中运行的所有任务都是“公平的”(图 1)
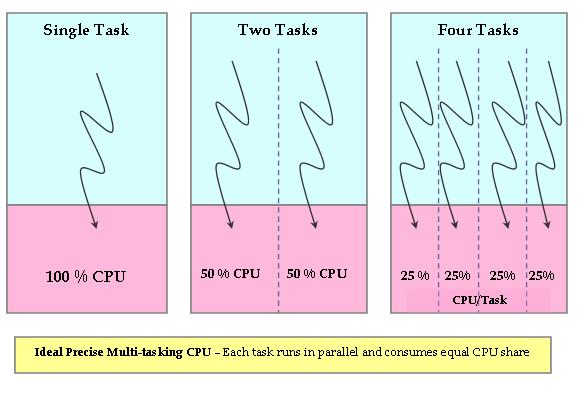
图 1. 理想、精确、多任务处理的 CPU
显然,这种理想的 CPU 是不存在的,但 CFS 试图在软件中模拟这样的处理器。 在实际的实际处理器上,在特定时间只能将一项任务分配给 CPU。 因此,所有其他任务都在此期间等待。 因此,当当前运行的任务获得 100% 的 CPU 功率时,所有其他任务获得 0% 的 CPU 功率。 这显然是不公平的(图2)。
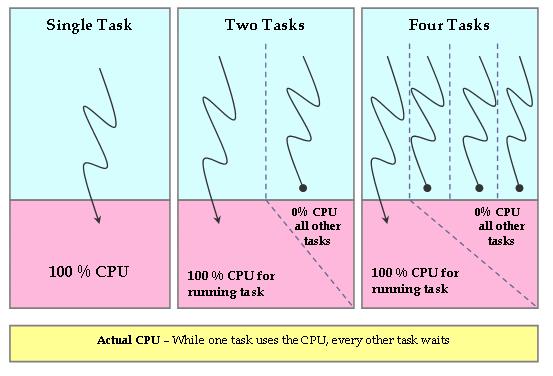
图 2. 实际硬件 CPU CFS 试图从系统中消除这种不公平。 CFS 尝试跟踪系统中每个进程可用的 CPU 的公平份额。因此,CFS 以实际 CPU 时钟速度的一小部分运行公平时钟。公平时钟的增长率是通过将挂墙时间(以纳秒为单位)除以等待的进程总数来计算的。结果值是每个进程有权使用的 CPU 时间量。
当进程等待 CPU 时,调度程序会跟踪它在理想处理器上使用的时间量。此等待时间由每个任务的 wait_runtime 变量表示,用于对进程进行排序以进行调度并确定进程在被抢占之前允许执行的时间量。等待时间最长的进程(即最需要 CPU 的进程)由调度程序挑选并分配给 CPU。当这个进程运行时,它的等待时间减少,而其他等待任务的时间增加(因为它们在等待)。这实质上意味着在一段时间后,将有另一个等待时间最长的任务(最需要 CPU),并且当前正在运行的任务将被抢占。使用这个原则,CFS 尝试对所有任务公平,并且总是尝试让系统为每个进程提供零等待时间——每个进程都拥有相等的 CPU 份额(“理想的、精确的、多任务的 CPU”会做到这一点) )。内核 2.6.23 为了让 CFS 模拟“理想的、精确的、多任务处理的 CPU”,为每个可运行的进程提供相等的执行时间片,CFS 需要具备以下条件:
图 2. 实际硬件 CPU CFS 试图从系统中消除这种不公平。 CFS 尝试跟踪系统中每个进程可用的 CPU 的公平份额。因此,CFS 以实际 CPU 时钟速度的一小部分运行公平时钟。公平时钟的增长率是通过将挂墙时间(以纳秒为单位)除以等待的进程总数来计算的。结果值是每个进程有权使用的 CPU 时间量。当进程等待 CPU 时,调度程序会跟踪它在理想处理器上使用的时间量。此等待时间由每个任务的 wait_runtime 变量表示,用于对进程进行排序以进行调度并确定进程在被抢占之前允许执行的时间量。等待时间最长的进程(即最需要 CPU 的进程)由调度程序挑选并分配给 CPU。当这个进程运行时,它的等待时间减少,而其他等待任务的时间增加(因为它们在等待)。这实质上意味着在一段时间后,将有另一个等待时间最长的任务(最需要 CPU),并且当前正在运行的任务将被抢占。使用这个原则,CFS 尝试对所有任务公平,并且总是尝试让系统为每个进程提供零等待时间——每个进程都拥有相等的 CPU 份额(“理想的、精确的、多任务的 CPU”会做到这一点) )。内核 2.6.23 为了让 CFS 模拟“理想的、精确的、多任务处理的 CPU”,为每个可运行的进程提供相等的执行时间片,CFS 需要具备以下条件:
- 一种计算每个进程的公平 CPU 份额的机制。这是通过使用系统范围的运行队列 fair_clock 变量 (cfs_rq->fair_clock) 实现的。这个公平的时钟以实时的一小部分运行,因此当系统中有 N 个可运行任务时,它以理想的速度运行单个任务。例如,如果您有四个可运行的任务,fair_clock 的增加速度是挂墙时间的四分之一(这意味着 25% 的公平 CPU 功率)。
- 一种机制,用于跟踪每个进程在 CPU 分配给当前正在运行的任务时等待的时间。这个等待时间在每个进程的变量wait_runtime (process->wait_runtime) 中累积。
3. 红黑树(RBTree)
红黑树是一种自平衡二叉搜索树——一种通常用于实现关联数组的数据结构。它很复杂,但它的操作具有良好的最坏情况运行时间,并且在实践中是高效的。它可以在 O(log n) 时间内进行搜索、插入和删除,其中 n 是树中元素的数量。在红黑树中,叶节点不相关,不包含数据。这些叶子在计算机内存中不需要是显式的——空子指针可以编码这个子是叶子的事实——但是如果叶子确实是显式节点,它会简化一些在红黑树上操作的算法。为了节省内存,有时单个哨兵节点扮演所有叶节点的角色;从内部节点到叶节点的所有引用都指向哨兵节点。 (来源:维基百科。)
CFS 使用公平时钟和等待运行时来保持所有可运行任务按 rbtree 中的 rq->fair_clock – p->wait_runtime 键排序(参见红黑树侧栏)。因此,树中最左边的任务是“最需要 CPU 的任务”,CFS 选择最左边的任务并坚持下去。随着系统的前进,新唤醒的任务被越来越多地放入树中,越来越靠右——缓慢但肯定地让每个任务都有机会成为最左边的任务,从而在确定的时间内进入 CPU。
由于这种简单的设计,CFS 不再使用活动和过期的数组,也不再使用复杂的启发式方法来将任务标记为交互式与非交互式。
CFS 通过使用加权任务来实现优先级——每个任务根据其静态优先级分配一个权重。因此,在运行时,权重较低(优先级较低)的任务将比优先级较高的任务以更快的速度流逝。这意味着它的 wait_runtime 将比高优先级任务消耗得更快,因此与高优先级任务相比,低优先级任务将获得更少的 CPU 时间。
内核 2.6.24 CFS 已在 2.6.24 中进一步修改。虽然公平的基本概念仍然存在,但一些实现细节已经发生了变化。现在,任务不再追逐全局公平时钟(rq->fair_clock),而是相互追逐。引入了每个任务的时钟 vruntime,并使用近似平均值为新任务初始化此时钟。每个任务都会跟踪其运行时间并使用此参数在 RBTree 中排队。因此,运行最少的任务(CPU 需求最严重的任务)是 RBTree 的最左侧节点,将被调度程序选中。有关此实现的更多详细信息,请参阅参考资料。
在内核 2.6.24 中,CFS 的另一个主要补充是组调度。普通 CFS 试图对系统中运行的所有任务保持公平。例如,假设系统中共有 25 个可运行的进程。 CFS 试图通过为所有人分配 4% 的 CPU 来保持公平。然而,假设在这 25 个进程中,20 个属于用户 A,而 5 个属于用户 B。用户 B 处于固有劣势,因为 A 获得的 CPU 能力比 B 多。组调度试图消除这个问题。它首先尝试对一个组公平,然后对组内的单个任务公平。所以CFS在启用了组调度的情况下,会为每个用户A和B分配50%的CPU。A分配的50%份额将在A的20个任务之间公平分配,而另外50%的CPU时间将被分配在 B 的 5 个任务中相当。
调度类/模块化调度器 在内核 2.6.23 中,Linux 调度程序也已模块化。每个调度策略(SCHED_FIFO、SCHED_RR、SCHED_OTHER 等)都可以独立于基本调度程序代码实现。这种模块化类似于面向对象的类层次结构(图 3)。
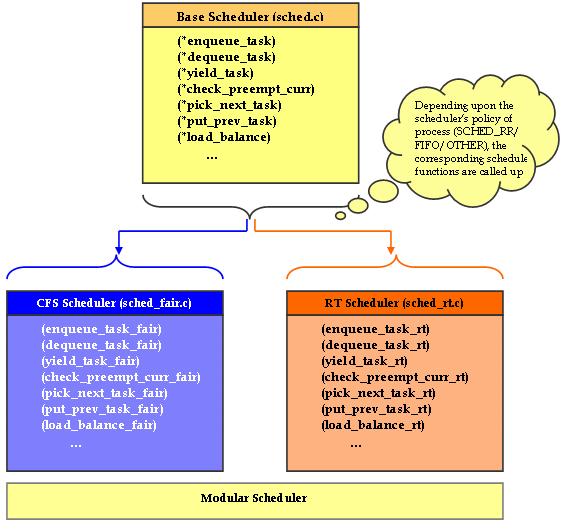
图 3. 模块化调度器
核心调度器不需要知道各个调度策略的实现细节。在内核 2.6.23 中,sched.c(旧内核中的“调度程序”)被分成以下文件以使调度程序模块化:
kernel/sched.c:包含通用调度程序的代码,从而暴露像 sched() 这样的函数。具体的调度策略在不同的文件中实现。
kernel/sched_fair.c:这是实现 CFS 调度器并提供 SCHED_NORMAL、SCHED_BATCH 和 SCHED_IDLE 调度策略的主要文件。
kernel/sched_rt.c:提供实时 (RT) 线程使用的 SCHED_RR 和 SCHED_FIFO 策略。
这些调度策略(fair 和 RT)中的每一个都向核心调度程序注册其函数指针。核心调度程序根据特定进程的调度策略调用适当的调度程序(fair 或 RT)。与 O(1) 调度程序一样,实时进程将比普通进程具有更高的优先级。 CFS 主要解决非实时进程,RT 调度器或多或少与以前相同(除了关于如何维护非活动/过期数组的一些更改)。
有了这个新的模块化调度程序,想要为特定策略编写新调度程序的人可以通过简单地向核心调度程序注册这些新策略函数来实现。
概括 CFS 设计的方法非常激进和创新。模块化调度程序等功能简化了将新调度程序类型集成到核心调度程序的任务。
资源
Linux 内核源代码 (2.6.23/2.6.24):sched-design-CFS.txt by Ingo Molnar
IBM Developer Works 文章 Multiprocessing with the Completely Fair Scheduler:kerneltrap.org/node/8059
与 CFS 相关的博客文章:immike.net/blog/2007/08/01/what-is-the-completely-fair-scheduler
Chandandeep Singh Pabla 在意法半导体工作。他在为多种操作系统上的多媒体 (DVD/STB) 芯片组开发嵌入式软件方面拥有丰富的经验。可以通过 chandandeep.pabla@st.com 与他联系。


