golang map
1. 并发读写测试
在golang中原生map 在并发场景下,同时读写是线程不安全的,无论key是否一样。以下是测试代码
package main
import "time"
func main() {
testMapReadWriteDiffKey()
}
func testMapReadWriteDiffKey() {
m := make(map[int]int)
go func() {
for {
m[100] = 100
}
}()
go func() {
for {
_ = m[12]
}
}()
select {}
}如上图的demo,并发读写map的不同key,运行结果如下

map读的时候会检查hashWriting标志, 如果有这个标志,就会报并发错误。写的时候会设置这个标志:h.flags |= hashWriting.设置完之后会取消这个标记。map的并发问题不是那么容易被发现, 可以利用-race参数来检查。map并发读写冲突检测机制不是本文的重点,不过感兴趣的同学可以通过以下链接深入了解下。这是源码,文章分析看这里。编译时的选项-race,为何能分析出并发问题,详见:go官方博客,文章分析,视频讲解
2. map+读写锁
在官方库sync.map没出来前,Go maps in action推荐的做法是使用map+RWLock,比如定义一个匿名struct变量,其包含map、RWLock,如下所示
var counter = struct{
sync.RWMutex
m map[string]int
}{m: make(map[string]int)}可以这样从counter中读数据
counter.RLock()
n := counter.m["some_key"]
counter.RUnlock()
fmt.Println("some_key:", n)可以这样往counter中写数据
counter.Lock()
counter.m["some_key"]++
counter.Unlock()那Go 1.9版本实现的sync.map和上面的这种实现方式有什么不同?它适用于哪些场景呢?它在哪些方面做了性能优化呢?
sync.map
sync.map是用读写分离实现的,其思想是空间换时间。和map+RWLock的实现方式相比,它做了一些优化:可以无锁访问read map,而且会优先操作read map,倘若只操作read map就可以满足要求(增删改查遍历),那就不用去操作write map(它的读写都要加锁),所以在某些特定场景中它发生锁竞争的频率会远远小于map+RWLock的实现方式。
接下来着重介绍下sync.map的源码,以了解其运作原理
1. 变量介绍
1.1 结构体Map
type Map struct {
// 互斥锁mu,操作dirty需先获取mu
mu Mutex
// read是只读的数据结构,访问它无须加锁,sync.map的所有操作都优先读read
// read中存储结构体readOnly,readOnly中存着真实数据---entry(详见1.3),read是dirty的子集
// read中可能会存在脏数据:即entry被标记为已删除(详见1.3)
read atomic.Value // readOnly
// dirty是可以同时读写的数据结构,访问它要加锁,新添加的key都会先放到dirty中
// dirty == nil的情况:1.被初始化 2.提升为read后,但它不能一直为nil,否则read和dirty会数据不一致。
// 当有新key来时,会用read中的数据 (不是read中的全部数据,而是未被标记为已删除的数据,详见3.2)填充dirty
// dirty != nil时它存着sync.map的全部数据(包括read中未被标记为已删除的数据和新来的数据)
dirty map[interface{}]*entry
// 统计访问read没有未命中然后穿透访问dirty的次数
// 若miss等于dirty的长度,dirty会提升成read,提升后可以增加read的命中率,减少加锁访问dirty的次数
misses int
}1.2 结构体readOnly
type readOnly struct {
m map[interface{}]*entry
amended bool
}1.1的结构read存的就是readOnly,m是一个map,key是interface,value是指针entry,其指向真实数据的地址,amended等于true代表dirty中有readOnly.m中不存在的entry
1.3 结构体entry
type entry struct {
// p == nil:entry已从readOnly中删除但存在于dirty中
// p == expunged:entry已从Map中删除且不在dirty中
// p == 其他值:entry为正常值
p unsafe.Pointer // *interface{}
}entry中的指针p指向真正的value所在的地址,dirty和readOnly.m存的值类型就是*entry。这里的nil和expunged有什么作用呢?只要nil不可以吗?对于这些问题后面会一一解读。
2. 函数介绍
下面介绍下sync.Map的四个方法:Store、Load、Delete、Range
2.1 Load方法
- 图解

- 源码分析
- Load方法用来加载sync.Map中的值,入参是key,返回值是对应的value以及value存在与否
func (m *Map) Load(key interface{}) (value interface{}, ok bool) {
// 从m.read中换出readOnly,然后从里面找key,这个过程不加锁
read, _ := m.read.Load().(readOnly)
e, ok := read.m[key]
// readOnly中不存在此key但Map.dirty可能存在
if !ok && read.amended {
// 加锁访问Map.dirty
m.mu.Lock()
// 双重检测:若加锁前Map.dirty被替换为readonly,则前面m.read.Load().(readOnly)无效,需
// 要再次检查
read, _ = m.read.Load().(readOnly)
e, ok = read.m[key]
// read.m没有此key && dirty里有可能有(dirty中有read.m没有的数据)
if !ok && read.amended {
// 从dirty中获取key对应的entry
e, ok = m.dirty[key]
// 无论Map.dirty中是否有这个key,miss都加一,若miss大小等于dirty的长度,dirty中的元素会被
// 加到Map.read中
m.missLocked()
}
m.mu.Unlock()
}
if !ok {
return nil, false
}
// 若entry.p被删除(等于nil或expunged)返回nil和不存在(false),否则返回对应的值和存在(true)
return e.load()
}Map.dirty是如何提升为Map.read的呢?让我们来看下missLocked方法
func (m *Map) missLocked() {
// 访问一次Map.dirty,misses就要加一
m.misses++
if m.misses < len(m.dirty) {
return
}
// 当misses等于dirty的长度,m.dirty提升为readOnly,amended被默认赋值成false
m.read.Store(readOnly{m: m.dirty})
m.dirty = nil
m.misses = 0
}小结:
- Load方法会优先无锁访问readOnly,未命中后如果Map.dirty中可能存在这个数据就会加锁访问Map.dirty
- Load方法如果访问readOnly中不存在但dirty中存在的key,就要加锁访问Map.dirty从而带来额外开销。
2.2 Store方法
- 图解
- 源码解析
- Store方法往Map里添加新的key和value或者更新value
func (m *Map) Store(key, value interface{}) {
// 把m.read转成结构体readOnly
read, _ := m.read.Load().(readOnly)
// 若key在readOnly.m中且entry.p不为expunged(没有标记成已删除)即key同时存在于readOnly.m和dirty
// ,用CAS技术更新value 【注】:e.tryStore在entry.p == expunged时会立刻返回false,否则用CAS
// 尝试更新对应的value, 更新成功会返回true
if e, ok := read.m[key]; ok && e.tryStore(&value) {
return
}
// key不存在于readOnly.m或者entry.p==expunged(entry被标记为已删除),加锁访问dirty
m.mu.Lock()
// 双重检测:若加锁前Map.dirty被提升为readOnly,则前面的read.m[key]可能无效,所以需要再次检测key是
// 否存在于readOnly中
read, _ = m.read.Load().(readOnly)
// 若key在于readOnly.m中
if e, ok := read.m[key]; ok {
// entry.p之前的状态是expunged,把它置为nil
if e.unexpungeLocked() {
// 之前dirty中没有此key,所以往dirty中添加此key
m.dirty[key] = e
}
// 更新(把value的地址原子赋值给指针entry.p)
e.storeLocked(&value)
// 若key在dirty中
} else if e, ok := m.dirty[key]; ok {
// 更新(把value的地址原子赋值给指针entry.p)
e.storeLocked(&value)
// 来了个新key
} else {
// dirty中没有新数据,往dirty中添加第一个新key
if !read.amended {
// 把readOnly中未标记为删除的数据拷贝到dirty中
m.dirtyLocked()
// amended:true,因为现在dirty有readOnly中没有的key
m.read.Store(readOnly{m: read.m, amended: true})
}
// 把这个新的entry加到dirty中
m.dirty[key] = newEntry(value)
}
m.mu.Unlock()
}func (e *entry) tryStore(i *interface{}) bool {
for {
p := atomic.LoadPointer(&e.p)
if p == expunged {
return false
}
if atomic.CompareAndSwapPointer(&e.p, p, unsafe.Pointer(i)) {
return true
}
}
}func (e *entry) unexpungeLocked() (wasExpunged bool) {
return atomic.CompareAndSwapPointer(&e.p, expunged, nil)
}func (m *Map) dirtyLocked() {
if m.dirty != nil { // 只要调用dirtyLocked,此时dirty肯定等于nil
return
}
// dirty为nil时,把readOnly中没被标记成删除的entry添加到dirty
read, _ := m.read.Load().(readOnly)
m.dirty = make(map[interface{}]*entry, len(read.m))
for k, e := range read.m {
// tryExpungeLocked函数在entry未被删除时【e.p!=expunged&&e.p!=nil】返回false,在
// e.p==nil时会将其置为expunged并返回true
if !e.tryExpungeLocked() {
m.dirty[k] = e // entry没被删除,把它添加到dirty中
}
}
}小结:
- Store方法优先无锁访问readOnly,未命中会加锁访问dirty
- Store方法中的双重检测机制在下面的Load、Delete、Range方法中都会用到,原因是:加锁前Map.dirty可能已被提升为Map.read,所以加锁后还要再次检查key是否存在于Map.read中
- dirtyLocked方法在dirty为nil(刚被提升成readOnly或者Map初始化时)会从readOnly中拷贝数据,如果readOnly中数据量很大,可能偶尔会出现性能抖动。
- sync.map不适合用于频繁插入新key-value的场景,因为此操作会频繁加锁访问dirty会导致性能下降。更新操作在key存在于readOnly中且值没有被标记为删除(expunged)的场景下会用无锁操作CAS进行性能优化,否则也会加锁访问dirty
2.3 Delete方法
- 图解
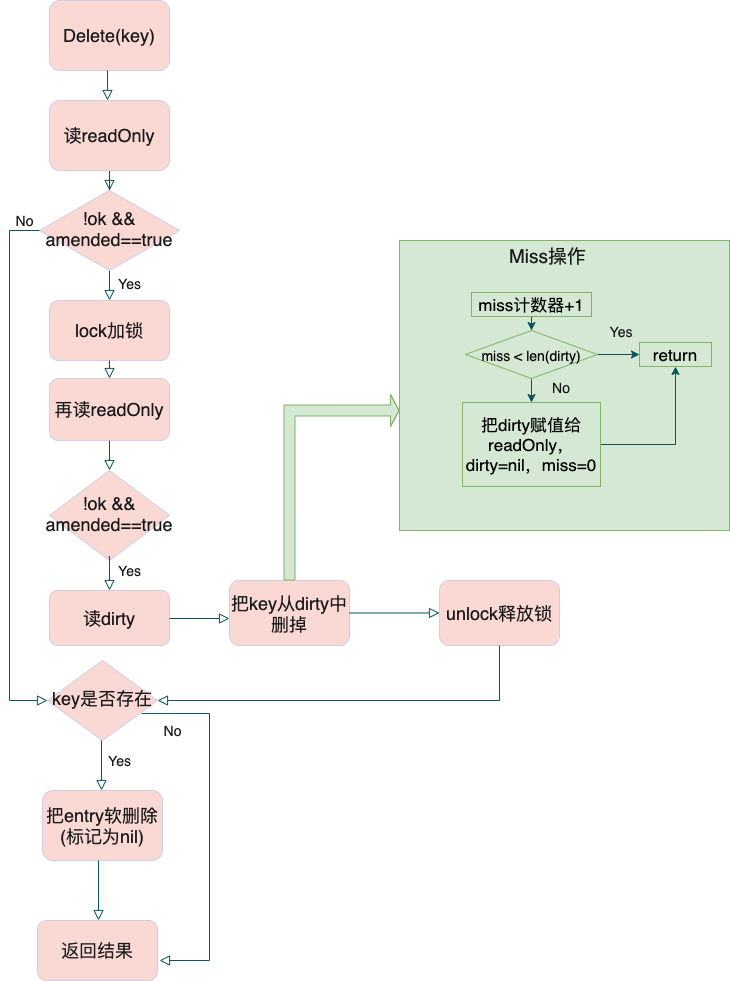
- 源码解析
- Delete方法把key从Map中删掉,返回被删除的值和是否删除成功,它底层调用的是LoadAndDelete
func (m *Map) LoadAndDelete(key interface{}) (value interface{}, loaded bool) {
// 从m.read中换出readOnly,然后从里面找key,此过程不加锁
read, _ := m.read.Load().(readOnly)
e, ok := read.m[key]
// readOnly不存在此key,但dirty中可能存在
if !ok && read.amended {
// 加锁访问dirty
m.mu.Lock()
// 双重检测:若加锁前Map.dirty被替换为readonly,则前面m.read.Load().(readOnly)无
// 效,需要再次检查
read, _ = m.read.Load().(readOnly)
e, ok = read.m[key]
// readOnly不存在此key,但是dirty中可能存在
if !ok && read.amended {
e, ok = m.dirty[key]
delete(m.dirty, key)
m.missLocked()
}
m.mu.Unlock()
}
if ok {
// 如果entry.p不为nil或者expunged,则把entry.p软删除(标记为nil)
return e.delete()
}
return nil, false
}func (e *entry) delete() (value interface{}, ok bool) {
for {
p := atomic.LoadPointer(&e.p)
if p == nil || p == expunged {
return nil, false
}
// e.p是真实值,把它置为nil
if atomic.CompareAndSwapPointer(&e.p, p, nil) {
return *(*interface{})(p), true
}
}
}小结:
- 删除readOnly中存在的key,可以不用加锁
- 如果删除readOnly中不存在的或者Map中不存在的key,都需要加锁。
2.4 Range方法
- 图解
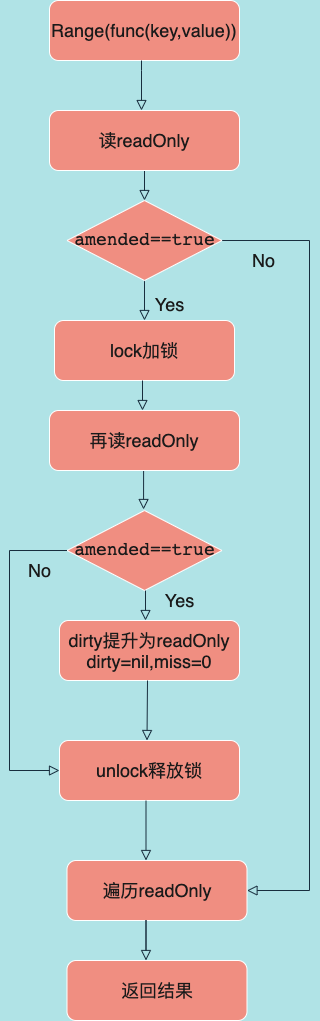
- 源码解析
- Range方法可遍历Map,参数是个函数(入参:key和value,返回值:是否停止遍历Range方法)
func (m *Map) Range(f func(key, value interface{}) bool) {
read, _ := m.read.Load().(readOnly)
if read.amended { // dirty存在readOnly中不存在的元素
// 加锁访问dirty
m.mu.Lock()
// 再次检测read.amended,因为加锁前它可能已由true变成false
read, _ = m.read.Load().(readOnly)
if read.amended {
// readOnly.amended被默认赋值成false
read = readOnly{m: m.dirty}
m.read.Store(read)
m.dirty = nil
m.misses = 0
}
m.mu.Unlock()
}
// 遍历readOnly.m
for k, e := range read.m {
v, ok := e.load()
if !ok {
continue
}
if !f(k, v) {
break
}
}
}小结:
- Range方法Map的全部key都存在于readOnly中时,是无锁遍历的,性能最高
- Range方法在readOnly只存在Map中的部分key时,会一次性加锁拷贝dirty的元素到readOnly,减少多次加锁访问dirty中的数据
3. sync.map总结
3.1 使用场景
sync.Map更适合读多更新多而插入新值少的场景(appendOnly模式,尤其是key存一次,多次读而且不删除的情况),因为在key存在的情况下读写删操作可以不用加锁直接访问readOnly
不适合反复插入与读取新值的场景,因为这种场景会频繁操作dirty,需要频繁加锁和更新read【此场景github开源库orcaman/concurrent-map更合适】
3.2 设计点:expunged
entry.p取值有3种,nil、expunged和指向真实值。那expunged出现在什么时候呢?为什么要有expunged的设计呢?它有什么作用呢?
1. 什么时候expunged会出现呢?
当用Store方法插入新key时,会加锁访问dirty,并把readOnly中的未被标记为删除的所有entry指针复制到dirty,此时之前被Delete方法标记为软删除的entry(entry.p被置为nil)都变为expunged,那这些被标记为expunged的entry将不会出现在dirty中。
2. 反向思维,如果没有expunged,只有nil会出现什么结果呢?
- 直接删掉entry==nil的元素,而不是置为expunged:在用Store方法插入新key时,readOnly数据拷贝到dirty时直接把为ni的entry删掉。但这要对readOnly加锁,sync.map设计理念是读写分离,所以访问readOnly不能加锁。
- 不删除entry==nil的元素,全部拷贝:在用Store方法插入新key时,readOnly中entry.p为nil的数据全部拷贝到dirty中。那么在dirty提升为readOnly后这些已被删除的脏数据仍会保留,也就是说它们会永远得不到清除,占用的内存会越来越大。
- 不拷贝entry.p==nil的元素:在用Store方法插入新key时,不把readOnly中entry.p为nil的数据拷贝到dirty中,那在用Store更新值时,就会出现readOnly和dirty不同步的状态,即readOnly中存在dirty中不存在的key,那dirty提升为readOnly时会出现数据丢失的问题。
4. sync.map的其他问题
为什么sync.map不实现len方法?
个人觉得还是成本和收益的权衡。
1. 实现len方法要统计readOnly和dirty的数据量,势必会引入锁竞争,导致性能下降,还会额外增加代码实现复杂度
2. 对sync.map的并发操作导致其数据量可能变化很快,len方法的统计结果参考价值不大。
orcanman/concurrent-map
orcaman/concurrent-map的适用场景是:反复插入与读取新值,其实现思路是:对go原生map进行分片加锁,降低锁粒度,从而达到最少的锁等待时间(锁冲突)
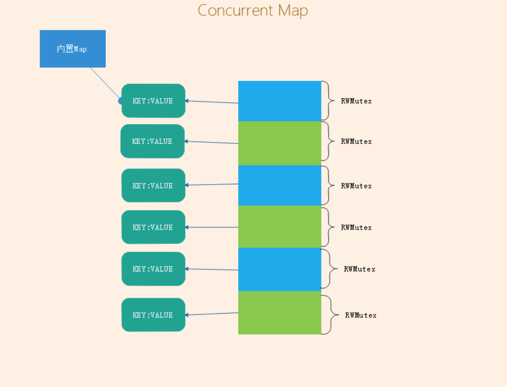
它的实现比较简单,截取部分源码如下
1. 数据结构
// SHARD_COUNT 分片大小
var SHARD_COUNT = 32
type ConcurrentMap []*ConcurrentMapShared
// ConcurrentMapShared 分片的并发map
type ConcurrentMapShared struct {
items map[string]interface{}
sync.RWMutex // 访问内部map都需要先获取读写锁
}
// New 创建一个concurrent map.
func New() ConcurrentMap {
m := make(ConcurrentMap, SHARD_COUNT)
for i := 0; i < SHARD_COUNT; i++ {
m[i] = &ConcurrentMapShared{items: make(map[string]interface{})}
}
return m
}2. 函数介绍
2.1 GET方法
// 先hash拿到key对应的分区号,然后加锁,读取值,最后释放锁和返回
func (m ConcurrentMap) Get(key string) (interface{}, bool) {
// Get shard
shard := m.GetShard(key)
shard.RLock()
// Get item from shard.
val, ok := shard.items[key]
shard.RUnlock()
return val, ok
}2.2 SET方法
// 先hash拿到key对应的分区号,然后加锁,设置新值,最后释放锁
func (m ConcurrentMap) Set(key string, value interface{}) {
// Get map shard.
shard := m.GetShard(key)
shard.Lock()
shard.items[key] = value
shard.Unlock()
}2.3 Remove方法
// 先hash拿到key对应的分区号,然后加锁,删除key,最后释放锁
func (m ConcurrentMap) Remove(key string) {
// Try to get shard.
shard := m.GetShard(key)
shard.Lock()
delete(shard.items, key)
shard.Unlock()
}2.4 Count方法
// 分别拿到每个分片map中的元素数量,然后汇总后返回
func (m ConcurrentMap) Count() int {
count := 0
for i := 0; i < SHARD_COUNT; i++ {
shard := m[i]
shard.RLock()
count += len(shard.items)
shard.RUnlock()
}
return count
}2.5 Upsert方法
// 先hash拿到key对应的分区号,然后加锁,如果key存在就更新其value,否则插入新的k-v,释放锁并返回
func (m ConcurrentMap) Upsert(key string, value interface{}, cb UpsertCb) (res interface{}) {
shard := m.GetShard(key)
shard.Lock()
v, ok := shard.items[key]
res = cb(ok, v, value)
shard.items[key] = res
shard.Unlock()
return res
}后续
当然在其他业务场景中,我们可能更需要的是本地kv缓存组件库并要求它们支持键过期时间设置、淘汰策略、存储优化、gc优化等。 这时候可能我们就需要去了解freecache、gocache、fastcache、bigcache、groupcache等组件库了。
参考链接
https://stackoverflow.com/questions/45585589/golang-fatal-error-concurrent-map-read-and-map-write/45585833
https://github.com/golang/go/issues/20680
https://github.com/golang/go/blob/master/src/sync/map.go
https://github.com/orcaman/concurrent-map